Builds
GPU kernels, inference engines, training pipelines, and agents. Each project ships benchmarks and code you can run.
Kernels
Triton Kernels for LLM Inference
Seven kernels from scratch — vector add through FlashAttention forward — each with a PyTorch baseline and H100 benchmarks.
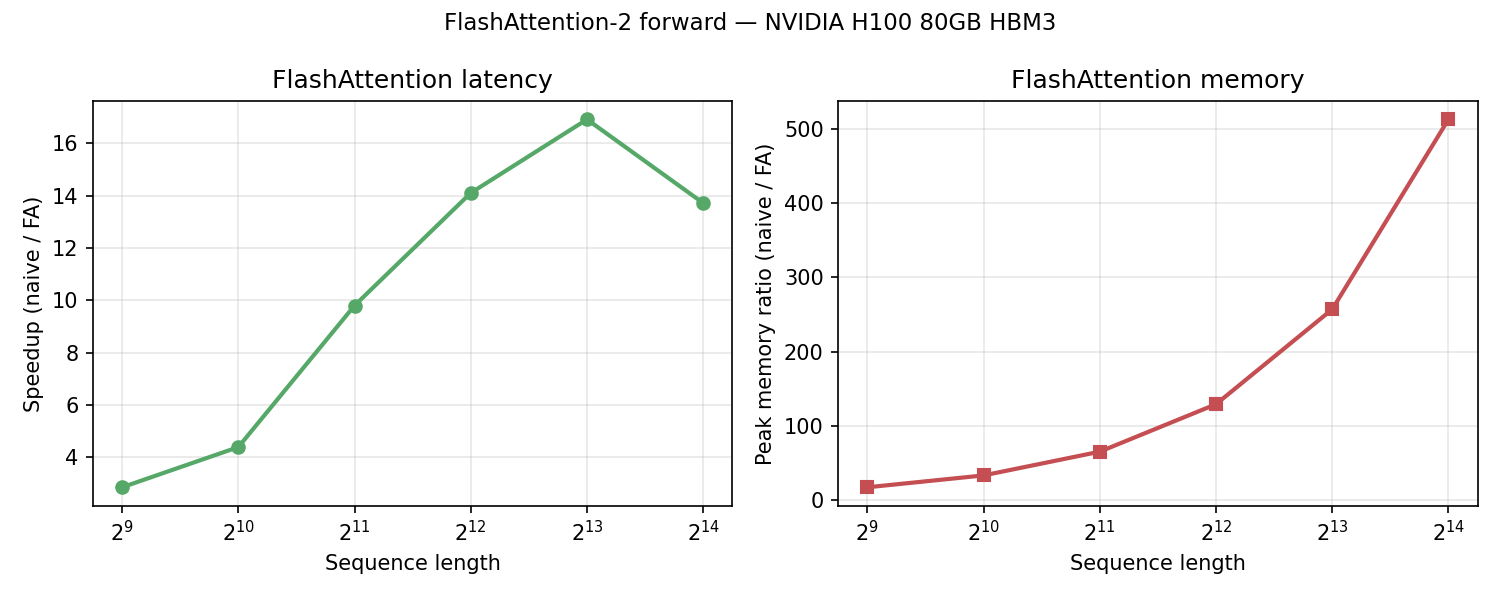
Seven kernels written from scratch — vector add → tiled GEMM → fused softmax / RMSNorm / RoPE → FlashAttention-2 forward — each with a PyTorch baseline and H100 benchmarks. The goal was to understand exactly what happens below PyTorch's abstraction boundary: where memory bandwidth gets wasted, which ops can be fused, and how the roofline model predicts what's achievable.
- Vector add (kernel 1): baseline to learn Triton's grid/block model and how threads map to memory. Gets you comfortable before the complex stuff.
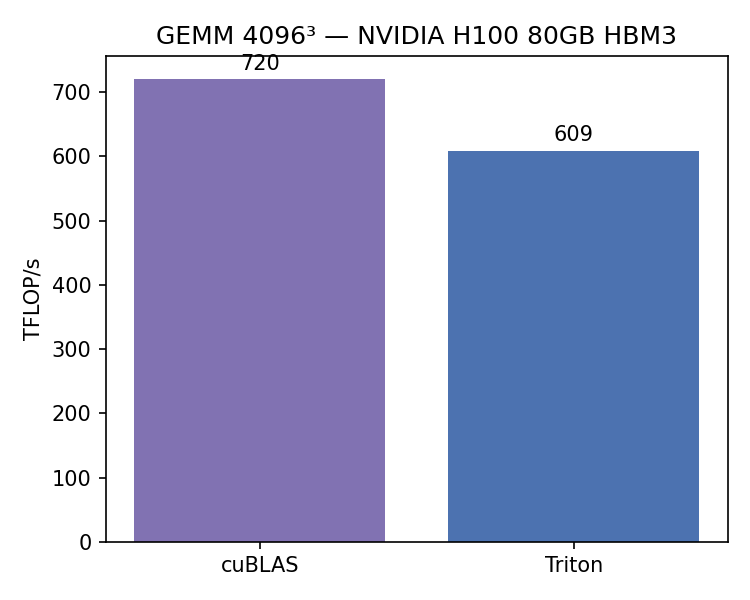
- Tiled GEMM (kernel 2): five progressive optimizations — memory coalescing, shared memory tiling, thread coarsening, vectorized loads, warp-level efficiency. Reaches 85% of cuBLAS on 4096³ shapes.
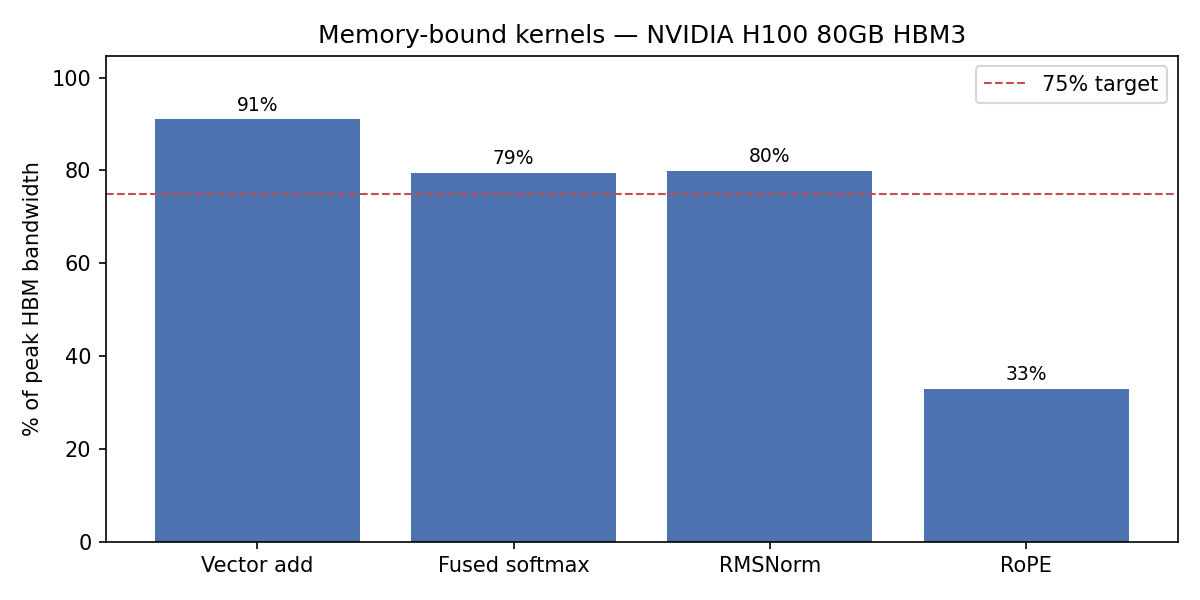
- Fused softmax + online softmax (kernels 3–4): naive PyTorch softmax does three HBM passes (max, subtract, exp+sum). The fused kernel does it in one using Welford-style online reduction. Online softmax extends this for numerical stability at long sequences.
- Fused RMSNorm and RoPE (kernels 5–6): PyTorch runs these as separate ops with separate HBM read/write cycles each. Fusing them saves a full round-trip per operation and hits ~80% peak HBM bandwidth.
- FlashAttention-2 forward (kernel 7): tiled SRAM computation with causal masking — O(N) memory instead of O(N²) for the naive attention matrix. The memory gap is what makes 8K+ context feasible on a single GPU.
Inference & serving
mini-vllm
~500-line inference engine: paged KV cache, block allocator, and continuous batching. Same ideas as vLLM, one file per concept.
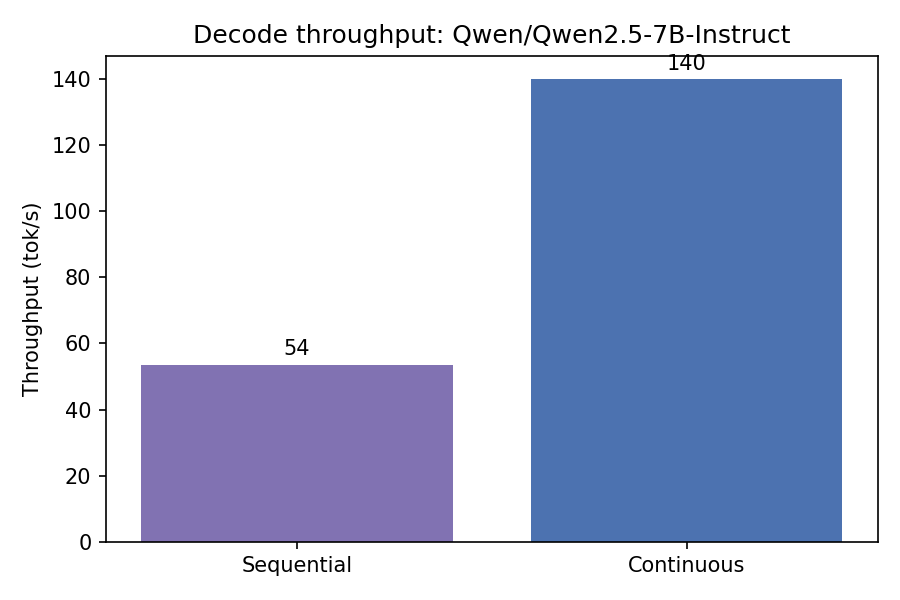
A ~500-line single-GPU inference engine that implements the core ideas behind vLLM: paged KV cache, a block allocator, and continuous batching. Stripped to one file per concept so you can read through it and understand each moving part. The benchmarks show concretely what each technique buys you.
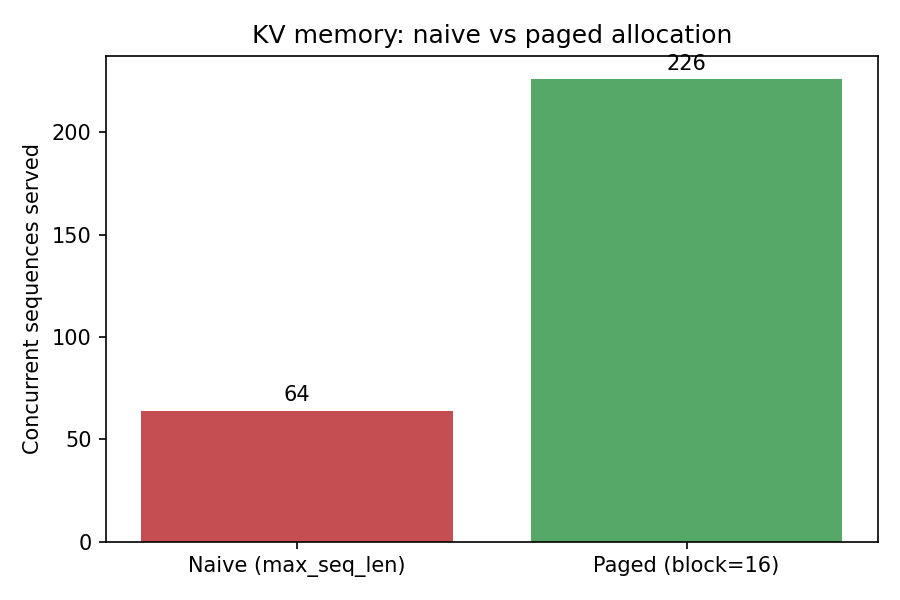
- PagedAttention: standard inference allocates a full
[max_seq_len × layers × heads × dim]KV tensor per request upfront — most of it wasted when sequences finish early. mini-vllm pre-allocates one shared GPU pool, maps each sequence to a list of fixed-size blocks via a block table, and writes/reads through that table on every forward pass. Blocks return to the free pool when a sequence finishes. - BlockAllocator: manages the shared pool with ref-counted
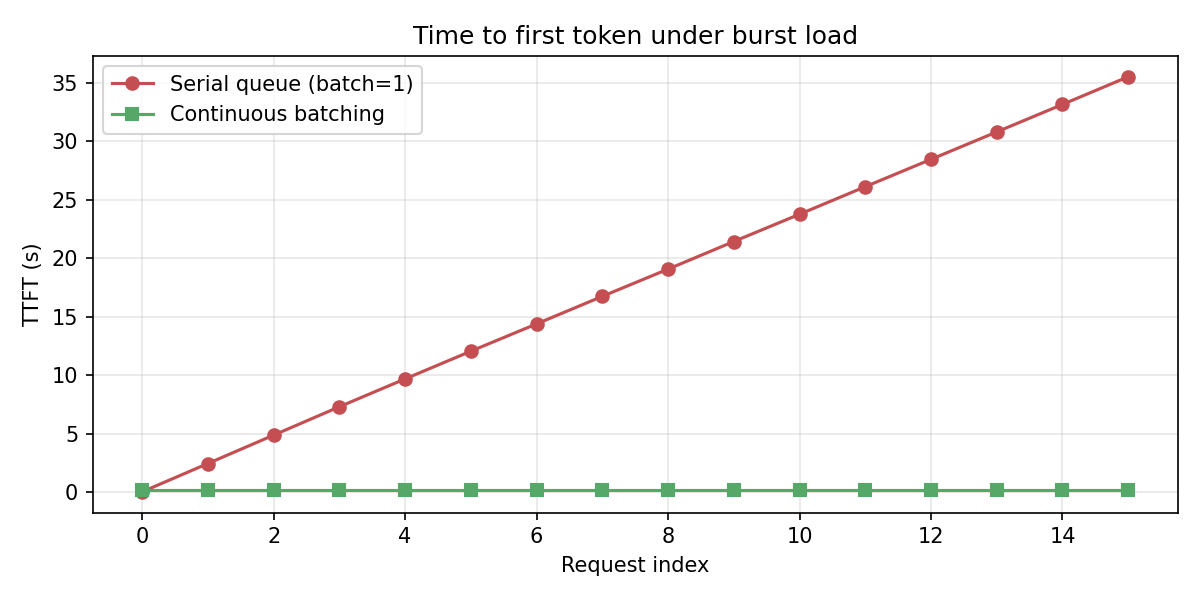
PhysicalBlockobjects. Sequences grow by requesting one more block at a time — no fragmentation from variable-length sequences. - Continuous batching: a naive server waits for a full batch to complete before starting new requests. mini-vllm's FCFS scheduler dynamically slots new requests into the running batch mid-step — GPU never idles waiting for stragglers.
- Engine loop:
add_request → schedule → prefill pass → decode steps → sample → free blocks. Prefill and decode are separate phases because their compute profiles differ: prefill is compute-bound (long sequence), decode is memory-bound (single token, large KV). - Model runner: loads Llama/Qwen weights from HuggingFace and patches the stock attention layers with
PagedAttentionat init time — reuses the original projection weights, only swaps the attention mechanism.
Training
reasoning
DeepSeek-R1-style post-training in raw PyTorch: SFT on OpenR1-Math CoT traces, then Dr.GRPO with exact-match rewards. No TRL, no HuggingFace Trainer.
Post-training pipeline for math reasoning on Qwen2.5-3B. Reimplements the DeepSeek-R1 workflow: supervised fine-tuning on chain-of-thought traces, then reinforcement learning with verifiable rewards via Dr.GRPO. Training loops, losses, and FSDP sharding are implemented from scratch.
- SFT: fine-tune on a 10k subset of OpenR1-Math CoT traces with loss masked on prompts.
- Dr.GRPO: group-relative policy optimization with clipped policy loss and exact-match rewards. No critic model, no reference model.
- Eval: GSM8K and MATH500 with a fixed CoT prompt harness and identical decode settings across checkpoints.
- Systems: FSDP full-shard across 2 GPUs, bf16 + activation checkpointing, parameter sweeps before RL to fit batch size and sequence length.
Agents
coding-agent
Plan-then-execute CLI agent for real git repos. Self-hosted on vLLM — no API keys, no rate limits.
CLI agent that plans a task against a real git repo, then runs a tool loop (read, write, grep, bash) until the task is complete. Self-hosted on vLLM — no API dependency, no rate limits, and roughly 100× cheaper than GPT-4 ReAct at scale.
- Plan-then-execute: model first outputs a full plan in one pass, then enters a tool loop — separating reasoning from execution reduces mid-task context confusion and prevents the model from changing strategy halfway through a file write.
- Tools:
file_read(any file in the repo),file_write(create or patch),grep(regex search across the working tree),bash_exec(shell commands, run tests, call linters). The loop continues until the model emits a done signal or hits the step budget. - Self-hosted inference: Qwen2.5-7B served via vLLM (same paged-KV stack as mini-vllm above). Fully local — useful for private repos where sending code to an external API is a concern.
- LangSmith tracing: optional export of the full thought/tool trace — lets you replay any run and see exactly which tool call broke the task.
AI Agent Framework
Multi-step tool-use agent built from scratch. Sliding-window memory, MCP tools, and evaluated on the GAIA benchmark.
Multi-step tool-use agent built from scratch — no LangChain, no LangGraph — to understand what an agent actually does under the hood before using a framework. Sliding-window memory, session persistence, MCP tool integration, and evaluated on GAIA.
- Agentic loop from scratch: model outputs a thought, selects a tool, gets an observation, appends to context, repeats. Implementing this without a framework exposed where frameworks add value (state management, retries) and where they add noise (hidden prompts, magic error handling).
- Sliding-window memory: keeps the last N turns in context. Session state persists to disk — the agent can resume after interruption without losing tool history or intermediate results.
- MCP tools: web search, Python code execution (sandboxed), and file handling wired via the Model Context Protocol. MCP gives tool definitions a standard schema so the model knows exactly what arguments each tool expects.
- GAIA evaluation: GAIA is a benchmark of real-world multi-step tasks (finding specific facts, reasoning over documents, running code) designed to be hard for LLMs without tool use. It's the benchmark used to evaluate GPT-4o and Claude on agentic capability — running on it gives a direct comparison point.
- FastAPI backend, deployed live on HuggingFace Spaces.