A Guide to Fine-tuning Methods in LLMs (Part 1)
This blog explores various fine-tuning methods for Large Language Models. For a better understanding of the motivation behind these techniques, I recommend first reading my article on Memory Optimization in Deep Learning.
Understanding Fine-tuning vs Training
Key Distinction: Training involves starting with random weights, while fine-tuning starts with pre-trained model weights. This fundamental difference shapes our approach to model adaptation.
The Memory Challenge
When running large models on available hardware, you typically have two main options:
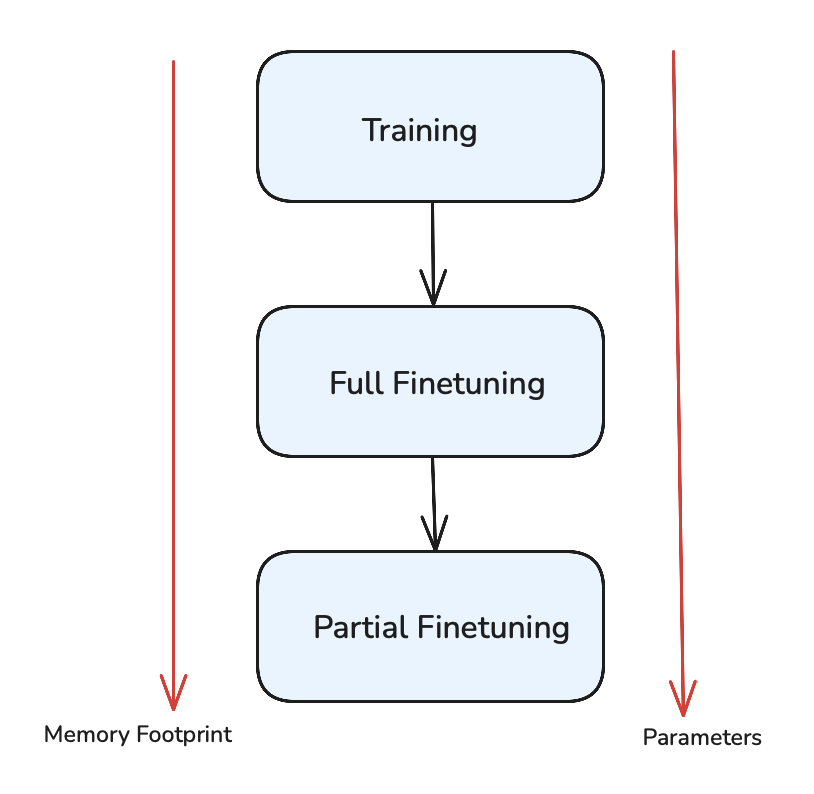
Evolution of Fine-tuning Approaches
1. Full Fine-tuning
In the early days of deep learning, when models had fewer parameters, full fine-tuning was the standard approach. This method updates all model weights during the adaptation process.
2. Partial Fine-tuning
As models grew larger, researchers began experimenting with partial fine-tuning, freezing about 10% of the model weights. While this reduced memory footprint, the performance benefits were limited. Meaningful improvements typically required fine-tuning at least 30% of the model parameters.
The critical question emerged: Could we achieve significant performance improvements while updating only a tiny fraction of parameters? This led to the development of Parameter-Efficient Fine-Tuning (PEFT) methods.
Parameter-Efficient Fine-Tuning (PEFT)
The core idea behind PEFT is strategic: introduce small trainable neural networks called "adapters" at carefully selected locations within the model. These adapters act as learnable interfaces between the model's frozen layers. During fine-tuning, the original pre-trained weights remain unchanged, and only these adapter parameters are updated, making the process highly efficient.
Advantages
- Parameter Efficient: Requires only a small fraction of trainable parameters
- Sample Efficient: Needs fewer examples for effective fine-tuning
- Memory Efficient: Significantly reduced memory footprint
Limitations
- Increased Inference Latency: Additional computation overhead during forward pass
- Architecture Modifications: Requires changes to model structure
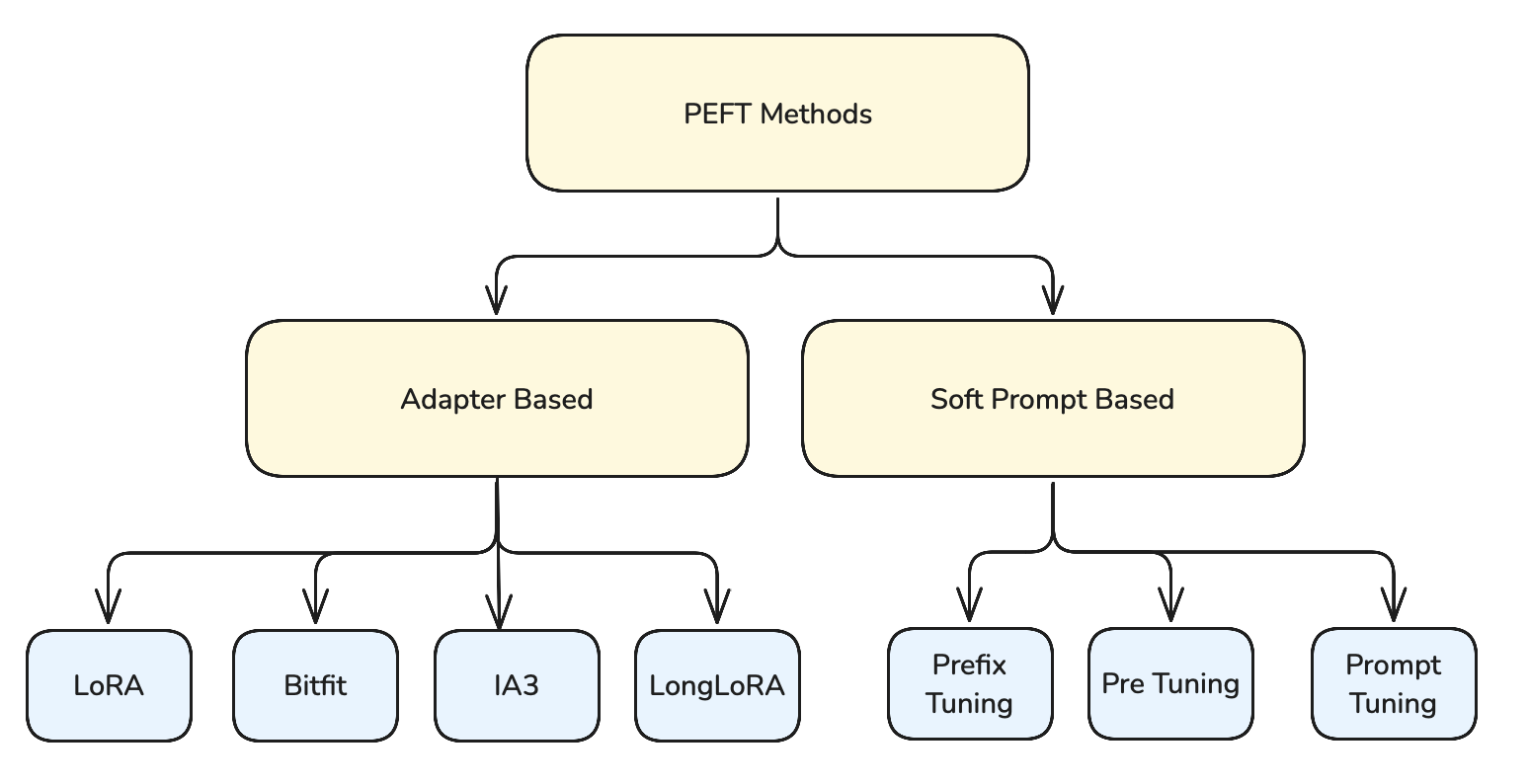
Understanding Prompt-Based Methods
Hard Prompting
Soft Prompting
Key Prompt-Based Methods
- Prefix Tuning: Adds trainable continuous tokens before specific layers
- Prompt Tuning: Prepends trainable embeddings to the input
- P-Tuning: Introduces trainable prompts at multiple positions
Think of soft prompts as the model learning a "language" of its own. For example, when fine-tuned on summarization tasks, the soft prompts might encode patterns that help the model recognize key information and generate concise outputs. While we can't "read" these embeddings directly, their effect on the model's behavior is measurable and consistent.
While these prompt-based methods showed promise, they haven't gained as much widespread adoption as more recent approaches like LoRA, which offers better efficiency and easier implementation.
Understanding SVD and Low-Rank Decomposition
Before diving into LoRA, let's understand the key concept behind it: low-rank matrix decomposition. Through a practical example using SVD (Singular Value Decomposition), we'll see how a large matrix can be represented using fewer parameters. This same principle is what makes LoRA efficient - it essentially adds a low-rank update (product of two smaller matrices) to the original weight matrix.
As expected, the matrix has rank 2, confirming that all its information can be represented using just two dimensions, despite being a 10×10 matrix. This is a key insight into why low-rank methods work.
SVD decomposes our matrix into three components, but remarkably, we only need to keep the first two singular values and their corresponding vectors. This is because these capture the essential structure of our matrix, while the remaining values are effectively zero.
This example demonstrates the power of low-rank decomposition: we could perfectly replicate the behavior of the original weights using far fewer parameters. A and B combined have only 40 parameters (10×2 + 2×10 = 40), while the original W matrix had 100 parameters (10×10 = 100). This 60% reduction in parameters is exactly the kind of efficiency that makes LoRA so powerful.
Low-Rank Adaptation (LoRA)
The main idea of Low-Rank Adaptation (LoRA) is to decompose weight updates into low-rank matrices, train these smaller matrices, and then add their product back to the original weights.
Let's break down how LoRA works: Instead of directly updating the large weight matrices of the model, LoRA introduces two smaller matrices (A and B) whose product approximates the weight update. This approach significantly reduces the number of trainable parameters while maintaining model quality.
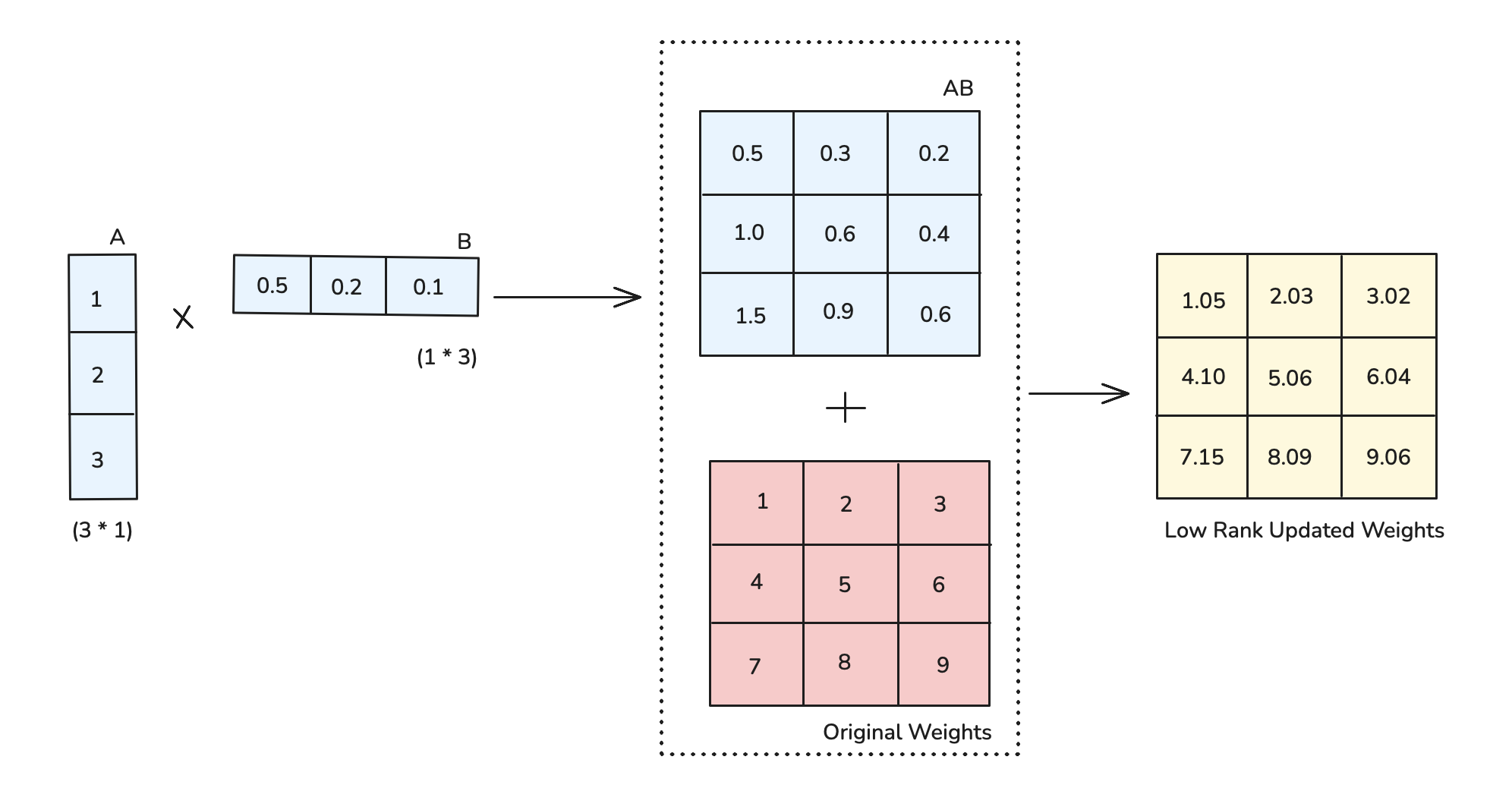
Key Advantages of LoRA
Unlike traditional adapter methods that add extra layers and increase inference latency, LoRA's design offers a unique advantage: the trained matrices can be merged with the original weights at inference time, resulting in zero additional latency.
Serving LoRA Models
One of LoRA's most powerful features is its flexibility during inference. There are two main approaches:
Merged Weights
- Add LoRA updates (A×B) back to original weights
- Zero inference overhead
- Same memory footprint as original model
- Best for single-task deployment
Separate Weights
- Keep LoRA matrices separate
- Switch between different fine-tuned versions
- Combine multiple LoRA adaptations
- Ideal for multi-task scenarios
This flexibility allows for interesting deployment scenarios. For example, you could have a base model with different LoRA adaptations for different languages or tasks, and dynamically choose or even combine them at inference time.
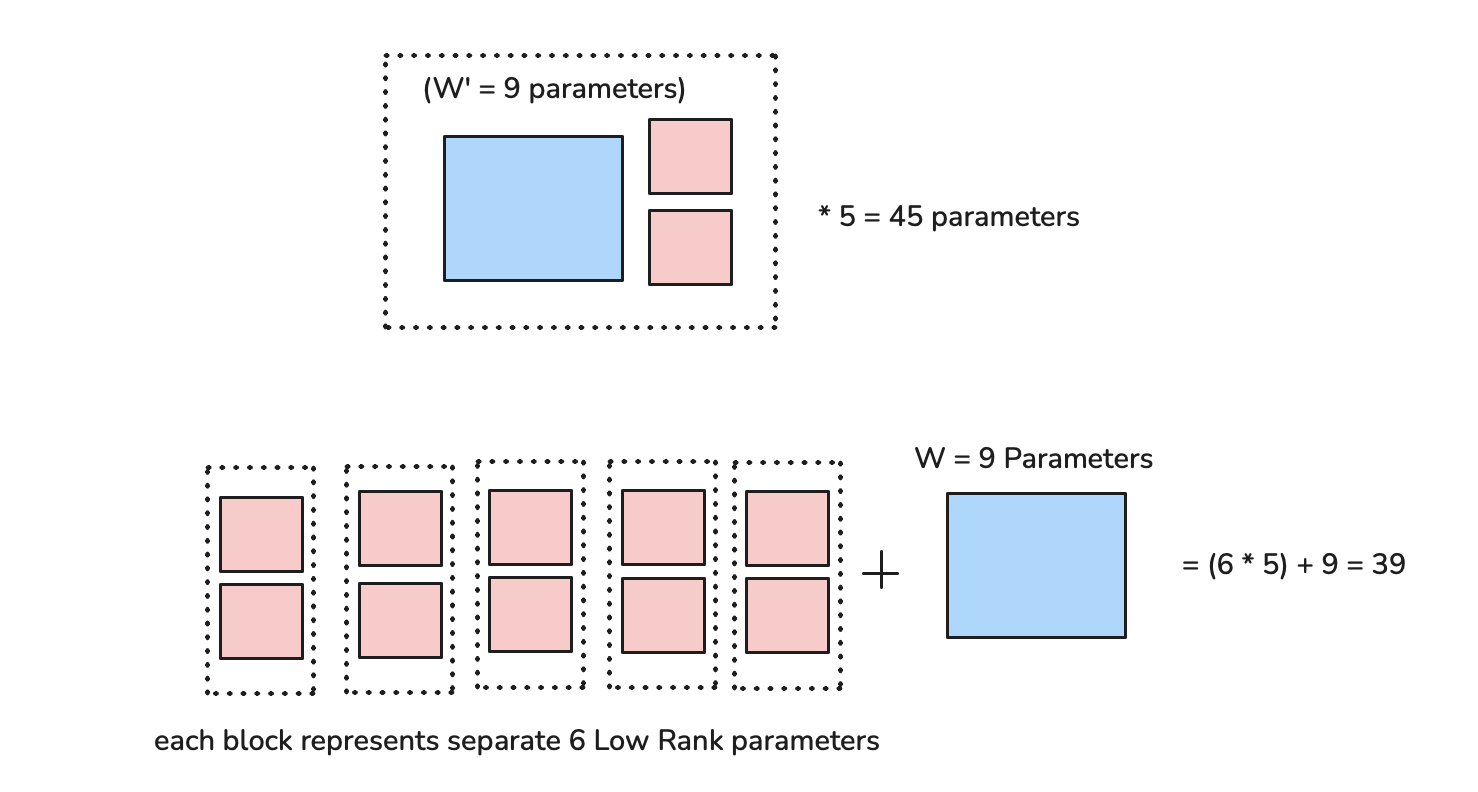
Storage Benefits of Separate LoRA Weights: A Simple Example
Let's say we have a small weight matrix W of size 3×3 (9 parameters) and 5 different customers:
Option 1 (Merged Weights): • Store 5 full matrices (Wʹ) of size 3×3 • Total storage: 9 parameters × 5 = 45 parameters
Option 2 (Separate LoRA): • Store 1 base matrix W (9 parameters) • Store 5 sets of LoRA matrices A(3×1) and B(1×3) • Each LoRA pair needs 6 parameters (3 + 3) • Total storage: 9 + (6 × 5) = 39 parameters
Even in this tiny example, separate storage saves ~13% space. The savings become much more dramatic with real-world model sizes and more customers.
QLoRA: Quantized LoRA
QLoRA combines the efficiency of LoRA with the memory benefits of quantization. It's a powerful approach that makes fine-tuning possible on consumer GPUs while maintaining model quality.
Key Components
- Base model weights are frozen and quantized (typically to 4-bit)
- LoRA parameters remain in full precision (16-bit)
- Gradients computed in full precision during backpropagation
Why This Works
- Most memory is in frozen weights - safe to quantize
- LoRA updates need precision for learning - kept in 16-bit
- Dequantization during forward pass preserves accuracy
Thanks for sticking till the end! In Part 2, we'll explore advanced topics including model merging and multitask fine-tuning. Stay tuned!